Online Dating: Quarantine Edition
You did it. You really did it.
You finally succumbed to quarantine fever and used your credit card to pay the membership fee for Match.com.
Of course, you’re skeptical about the whole “online dating” thing, but you’re optimistic and hopeful—and probably a little excited by the idea that true love might be (literally) just a mouse click away. Really, though, you’re just hoping the opportunity cost of spending $23.99/month will be worth it when you [sigh] finally meet that twenty-something, super-rich [insert famous celebrity here] look-alike who is (1) still single (no chance), (2) also a member of Match.com (never happen), and (3) of the opinion you’re more attractive than anyone else they could ever meet (highly unlikely). But you still play the lottery, so you believe anything is possible. (It’s an unfortunate consequence of our sociosexual evolution that callipygian gifts require payment in kind. I think Aristotle said that.)
Anyway, what now? Endless scrolling? Interminable thanks-but-no-thanks messages followed by hasty profile blocking? Wasted Friday and Saturday nights trying to get not-quite [said famous celebrity] 2.0 with the slightly unattractive aquiline profile to pay more attention to you than the comments on their Instagram selfies? There’s a better way. Say “no” to bad lighting and undercooked meat, and say “yes” to the dress the mathematics of probability optimization.
Proba…what?
Right.
What if I told you we can use the power and beauty of mathematics to give you the best chance of finding the lust love of your life? It’s true. Let’s say you’re willing to look at a total of t profile pictures sent to you by Match.com’s ostensibly preternatural algorithms. By rejecting the first r pictures, you will maximize the probability of finding your “ideal match.” (Call this person x.) I know: you don’t believe it, but it really is that simple. So, what’s the value of r for a given t? Technically, the answer is
First, some ground rules:
- Once you pass on a profile pic, you can’t go back. That person is gone forever. [insert crying emoji]
- Once you choose the value for r, you must reject every person from the first to the rth.
- You must choose the first profile (x > rth) that’s better than all the others you’ve seen.
- You must choose the last profile you see if you haven’t chosen anyone to that point.
- Once you choose someone, they are guaranteed to accept.
So, what do we know? Well, unfortunately, if your ideal match happens to show up within the first r profiles, you’re sunk. Because of rules 1 and 2, the probability of picking x—assuming x happens to arrive within the first r profiles—is, well, zero. To optimize your chances of picking x, we need to pick the optimized value for r. And to do that, we need to calculate the probability of x‘s location as Match.com sends profile pics to your inbox.

Okay, you can’t pick anyone within the first r profiles, but what if the (r+1)st profile is your dream date x? You’ll pick that person for sure, right? So, the probability is 1. But the probability of the (r+1)st profile being your dream date is (gulp) the worst it could be: 1/t (assuming a uniform distribution of profile pics). We take the product of these values; that is, “the probability you’d choose the (r+1)st profile assuming that person is better than the other r profiles” multiplied by “the probability this person happens to be located at the (r+1)st position in Match.com’s algorithm.” That happens to be [drum roll, please] (1)(1/t) = 1/t. For large t, that’s not so good. It gets better, though.
What if x is the (r+2)nd profile in your inbox? Well, you wouldn’t pick x in this scenario unless the (r+1)st profile wasn’t better than all the previous r profiles; in other words, the highest-rated profile to that point (i.e., the moment you received the (r+1)st profile) was one of the previous r profiles (otherwise, you would’ve picked the (r+1)st profile). The probability that the highest-rated profile of the first (r+1) profiles arrived within the first r profiles you rejected is very high, r/(r+1), and the probability that x happens to arrive in the (r+2)nd position remains 1/t. This is really the tricky part of the whole concept, so do yourself a favor and make sure you get it straight.
So, the total probability of the (r+2)nd profile being your dream date is the product of the two probability values we already calculated, that is,![t^{-1}\cdot r(r+1)^{-1}=r[t(r+1)]^{-1}.](https://s0.wp.com/latex.php?latex=t%5E%7B-1%7D%5Ccdot+r%28r%2B1%29%5E%7B-1%7D%3Dr%5Bt%28r%2B1%29%5D%5E%7B-1%7D.&bg=ffffff&fg=1c1c1c&s=-1&c=20201002)
![p(r,t)=t^{-1}+r[t(r+1)]^{-1}+r[t(r+2)]^{-1}+\cdots+r[t(t-1)]^{-1}](https://s0.wp.com/latex.php?latex=p%28r%2Ct%29%3Dt%5E%7B-1%7D%2Br%5Bt%28r%2B1%29%5D%5E%7B-1%7D%2Br%5Bt%28r%2B2%29%5D%5E%7B-1%7D%2B%5Ccdots%2Br%5Bt%28t-1%29%5D%5E%7B-1%7D&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
and after factoring out r/t, this simplifies to
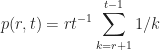
which is simply an r-mulitple of the average of the individual probabilities the jth candidate will be x with

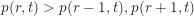
Taking the first case, we have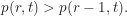
![\displaystyle (r-1)t^{-1}\Big[(r-1)^{-1}+r^{-1}+(r+1)^{-1}\cdots+(t-1)^{-1}\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%28r-1%29t%5E%7B-1%7D%5CBig%5B%28r-1%29%5E%7B-1%7D%2Br%5E%7B-1%7D%2B%28r%2B1%29%5E%7B-1%7D%5Ccdots%2B%28t-1%29%5E%7B-1%7D%5CBig%5D&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
![\displaystyle rt^{-1}\Big[r^{-1}+(r+1)^{-1}+\cdots + (t-1)^{-1}\Big]>](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+rt%5E%7B-1%7D%5CBig%5Br%5E%7B-1%7D%2B%28r%2B1%29%5E%7B-1%7D%2B%5Ccdots+%2B+%28t-1%29%5E%7B-1%7D%5CBig%5D%3E&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
Multiplying by t and distributing r-1 into the first term on the RHS gives us (1)
![\displaystyle 1+(r-1)\Big[r^{-1}+(r+1)^{-1}+\cdots + (t-1)^{-1}\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+1%2B%28r-1%29%5CBig%5Br%5E%7B-1%7D%2B%28r%2B1%29%5E%7B-1%7D%2B%5Ccdots+%2B+%28t-1%29%5E%7B-1%7D%5CBig%5D&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
![\displaystyle r\Big[r^{-1}+(r+1)^{-1}+\cdots + (t-1)^{-1}\Big]>](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+r%5CBig%5Br%5E%7B-1%7D%2B%28r%2B1%29%5E%7B-1%7D%2B%5Ccdots+%2B+%28t-1%29%5E%7B-1%7D%5CBig%5D%3E&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
Notice the bracketed expressions in both the LHS/RHS are equal! Now, we only have to deal with coefficients. Let’s do that. Subtracting the LHS from the RHS leaves us with
![\displaystyle 0>1-\Big[r^{-1}+(r+1)^{-1}+\cdots + (t-1)^{-1}\Big]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+0%3E1-%5CBig%5Br%5E%7B-1%7D%2B%28r%2B1%29%5E%7B-1%7D%2B%5Ccdots+%2B+%28t-1%29%5E%7B-1%7D%5CBig%5D&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
which, after rearranging, becomes
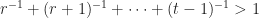
If we substitute r+1 into inequality (1) above and follow a similar calculation, we arrive at the other inequality we need:
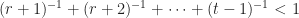
yielding the final result (2):

At this point, we can find the optimized value for r given an arbitrary t. Just make sure the above inequality still holds. For example, imagine Match.com sends you, say, seven profile pics. Then, we have 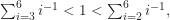
What does this mean? Well, given a total pool of seven profiles from which to choose (adhering to the aforementioned restrictions), you would automatically reject the first two profiles—no matter who they were—and then choose the very next profile that was better than the first two you rejected. Note: To calculate r, we use the smallest number of terms (based on the value of t we chose) to satisfy both sides of the inequality in (2).
Here are some calculations using the above machinery:



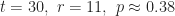
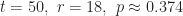
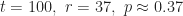
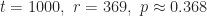
So, if you decide to consider a pool of 50 Match.com profiles, you’d automatically reject the first 18 and choose the first profile better than any of those 18 you rejected. That will give you a 37.43% chance of finding your ideal love match. Sure, you have about a 63% chance of missing x using this strategy, but any other strategy you choose will decrease your odds (assuming you follow the rules).[1]
One thing we can’t fail to notice is that as t gets larger, our p-value begins to settle around 37%.[2] That’s not a coincidence. In fact, the above inequalities relate to (a bounded subset of) the harmonic series: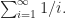
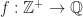


Taking the RHS, we have
![\displaystyle \int_{r}^{t}\!\!x^{-1}=\Big[\ln x\,\Big]_{r}^{t}=\,\ln\Big(\frac{t}{r}\Big)\,<\,\sum_{i=r}^{t-1} 1/i](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_%7Br%7D%5E%7Bt%7D%5C%21%5C%21x%5E%7B-1%7D%3D%5CBig%5B%5Cln+x%5C%2C%5CBig%5D_%7Br%7D%5E%7Bt%7D%3D%5C%2C%5Cln%5CBig%28%5Cfrac%7Bt%7D%7Br%7D%5CBig%29%5C%2C%3C%5C%2C%5Csum_%7Bi%3Dr%7D%5E%7Bt-1%7D+1%2Fi&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
and the LHS is
![\displaystyle \sum_{i=r+1}^{t-1} 1/i < \int_{r}^{t-1}\!\!x^{-1}=\Big[\ln x\Big]_{r}^{t-1}=\ln\Big(\frac{t-1}{r}\Big)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bi%3Dr%2B1%7D%5E%7Bt-1%7D+1%2Fi+%3C+%5Cint_%7Br%7D%5E%7Bt-1%7D%5C%21%5C%21x%5E%7B-1%7D%3D%5CBig%5B%5Cln+x%5CBig%5D_%7Br%7D%5E%7Bt-1%7D%3D%5Cln%5CBig%28%5Cfrac%7Bt-1%7D%7Br%7D%5CBig%29&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
Putting it all together, we have

As t and r grow larger, however, we find that

and the last inequality above suggests we’re “squeezing” the value of 1 from both sides, yielding the final calculation:
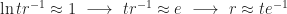
as claimed.
What’s great about this is that your chances don’t decrease the larger t is. Whether you’re willing to look through 15 profiles or 15,000, your optimized probability remains the same—about 37%. Also, the variable t doesn’t have to deal with profiles; it could involve, say, time. If you’ve allocated five months to find the best venue for your wedding, you’ll reject everything you see until (about) day 56 (= 150/e), at which point you’ll choose the first venue that’s better than every venue you’ve seen so far. Of course, venues aren’t like jilted dates: you can always circle back and choose a venue you’ve rejected, but the math works the same way given the assumptions.
So, there it is. You have nearly 2/5 probability of finding your ideal date using the above approach. That’s pretty good, actually. It’s not as good the probability the sun will rise tomorrow, but it’s a lot better than getting even a short-term run in the stock market.
Math even cares about your love life.
Footnotes:
[1] Some strategies alter your chances by modifying our restrictions (e.g., selecting merely one of the best candidates, allowing proposal rejections, having full information about the candidates, incurring costs to passing, etc.). (As an example, one prominent design suggests stopping at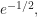
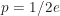
[2] This is why “no-information” optimal stopping is often referred to as “the 37% rule,” an algorithm originating in 1949 as Flood’s “fiancee problem“—recontextualized as “the secretary problem“—and later popularized by Martin Gardiner in the February 1960 issue of Scientific American.
References:
[1] B. Christian and T. Griffiths, Algorithms to Live By: The Computer Science of Human Decisions, New York: Henry Holt and Company, 2016.
[2] J. Billingham, Kissing the frog: A Mathematician’s Guide to Mating, Plus Magazine, 9 (2008) 1-3.

Leave a comment